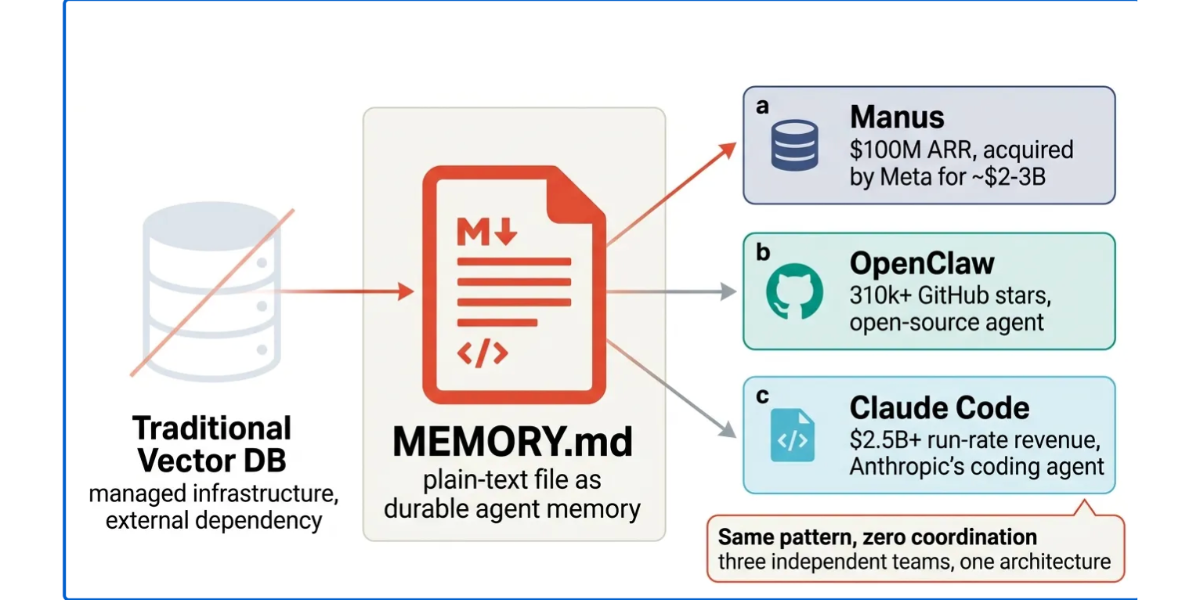
Most people assume that if you are building a serious AI agent, you need serious memory infrastructure from the start.
A vector database. A retrieval layer. A managed knowledge stack. A proper enterprise memory system.
That sounds sensible on paper. But when you look closely at how some of the most talked about agent products actually work, a simpler pattern keeps showing up.
They write things down in files.
Not as a toy solution. Not as a temporary hack. As a real architectural choice.
I spent time looking at how Manus, OpenClaw and Claude Code handle memory, and the same idea appears in all three. Files, usually Markdown files, act as the main interface for durable memory. The model reads them, writes them and uses them to carry state across long tasks and across sessions. Manus publicly described a “file system as context” approach in its engineering post, Anthropic documents CLAUDE.md and auto memory as the two ways Claude Code carries context across sessions, and OpenClaw’s public materials describe MEMORY.md, dated memory logs and a semantic index built over those files.
That matters because these are not all the same kind of product.
- Manus is an agent system built for complex multi step work
- Claude Code is Anthropic’s coding agent with persistent project guidance
- OpenClaw is a large open source personal AI assistant project with roughly 359,000 GitHub stars at the time of writing
Different products. Different users. Different teams.
Yet they keep circling back to the same conclusion: for a surprisingly large class of agent problems, text files are still one of the best memory substrates you can use.
What You Will Learn
In this article, I will break down:
- why file based memory keeps reappearing in serious agent systems
- why this matches the way language models actually work
- how Manus uses file writing as both a memory tool and a cost strategy
- how OpenClaw adds retrieval without replacing files as the source of truth
- how Claude Code turns file based memory into an official product pattern
- where Markdown files stop being enough
- when it is worth moving to a database

The Real Pattern Is Not “Markdown Beats Databases”
Let us get one thing clear from the start.
This is not an argument that databases are useless.
It is not an argument that retrieval does not matter.
It is not an argument that every agent should live forever inside a folder full of .md files.
The stronger point is this: the most successful agent stacks often start with files as the first class interface for state, and only add heavier infrastructure when the workflow actually demands it. That is exactly how Manus frames file storage in its context engineering post, how Anthropic frames CLAUDE.md and auto memory in Claude Code, and how OpenClaw describes its current memory setup with Markdown files plus a derived semantic index in SQLite.
That distinction matters.
The conversation should not be “files or databases?”
It should be “what is the simplest memory architecture that keeps the agent reliable, cheap, inspectable and easy to improve?”
In a lot of cases, that answer is still a Markdown file.
Why Files Fit LLMs So Well
LLMs already think in text
A language model does not need a special translation layer to understand a Markdown note.
It already works in text.
That means a file based memory system has an immediate advantage:
- the model can read it directly
- the model can write to it directly
- a human can inspect it directly
- the team can version it directly with Git
That is a big deal. Memory becomes visible instead of hidden. You can open a file and see what the agent “remembers” without needing a dashboard, a vector query interface or a back office memory service.
Files are easy to scope
Files also make scoping much easier than people admit.
You can separate memory into clear buckets:
- task plan
- working notes
- project rules
- durable preferences
- archived references
That is exactly the kind of structure LLMs handle well. A clean directory tree is often enough to express what matters now, what matters later and what should only load on demand.
Files keep humans in the loop
This is one of the most underrated advantages.
If the agent stores memory in Markdown, a human can audit it, correct it and prune it without friction. That keeps memory grounded. It stops the system becoming a black box where incorrect facts, stale assumptions or duplicated summaries quietly pile up.
In practice, simple systems win more often than clever systems because people can actually maintain them.
Manus: File Based Memory as a Cost and Attention Strategy
Manus is the clearest example of why this is more than a nice developer preference.
In its July 2025 engineering post, Manus said the average input to output token ratio in the system is around 100 to 1. The same post explains why KV-cache hit rate is such a critical production metric and gives a concrete Claude Sonnet example where cached input tokens cost about $0.30 per million tokens versus $3 per million for uncached input. It also explicitly recommends stable prompt prefixes, append only context and using the file system as context.
That one set of numbers explains a lot.
If your agent reads vastly more than it writes, input cost dominates. So the shape of your context matters. Stable context is not just cleaner for the model. It is cheaper.
Why todo.md is smarter than it looks
One of the best ideas in agent design is embarrassingly simple: keep a live task file.
A todo.md file does not just store progress. It keeps the current plan near the recent part of the context window, where the model is more likely to attend to it. That turns a plain text file into an attention control mechanism, not just a notebook.
This is important because retrieval alone does not solve the planning problem.
A database backed RAG system can bring back facts. It does not automatically keep the current plan hot. If the agent is 30 or 40 steps into a workflow, what it needs most is often not more facts. It needs a clear view of:
- what has already been done
- what still needs doing
- what the next action should be
- what constraints are currently active
A simple planning file does that beautifully.
Manus’s broader lesson
Manus also makes another point that many agent builders still miss. Long context is not free. Even when the model supports a big window, long context can still hurt performance and cost. That is why Manus describes a “Context Window = RAM, Filesystem = disk” style approach, where large observations can be dropped from immediate context as long as the URL, path or restorable reference remains available.
That is not just elegant. It is practical.
The agent keeps context lean without throwing information away forever.
OpenClaw: Retrieval on Top of Files, Not Instead of Files
If Manus shows the pure logic of file first memory, OpenClaw shows the next step.
Public OpenClaw materials describe a memory layout built around two main file types:
- MEMORY.md for curated long term memory
- memory/YYYY-MM-DD.md for daily logs
The same public issue discussion also describes tools such as memory_search and memory_get, and says the semantic index is built per agent in SQLite and updated through file watchers. Separate OpenClaw issue discussions also show hybrid query settings such as vectorWeight: 0.7, textWeight: 0.3, MMR diversification and optional temporal decay.
That is the hybrid architecture I think more teams will adopt.
Files remain the source of truth
This part matters most.
OpenClaw’s semantic layer sits over the files.
It does not replace them.
That means the notes are still readable, editable and versionable. Search becomes an optimisation layer, not the memory itself.
That is a much better default for most builders. You get the benefits of semantic retrieval without sacrificing transparency.
Why this is stronger than “just use a vector DB”
A lot of “just use a vector database” advice skips the hardest part of agent memory.
The hardest part is not merely storing embeddings.
It is preserving useful state across:
- long sessions
- context compaction
- changing priorities
- repeated corrections
- evolving project knowledge
A file first architecture handles that naturally. The agent writes durable notes. The next session reads them back. Then, when search becomes necessary, you index the notes.
That order matters.
Claude Code: When the Pattern Becomes Product
Claude Code is important because it takes this community pattern and turns it into an official workflow.
Anthropic’s documentation says each Claude Code session starts with a fresh context window and carries knowledge across sessions using two mechanisms:
- CLAUDE.md files that you write
- auto memory notes that Claude writes itself
The docs also say these are treated as context rather than enforced configuration, and that the first 200 lines or 25 KB of auto memory load into every session. They also explain that CLAUDE.md files can exist at multiple scopes including project, user and organisation level.
That is a very clean design.
CLAUDE.md works because it is scoped
One of the cleverest parts of Claude Code’s design is scope.
You do not dump every rule into one giant memory file. You split them by level:
Organisation level
Use this for shared security rules, coding standards and operational policies.
Project level
Use this for build commands, project architecture, conventions and recurring workflow guidance.
User level
Use this for personal preferences and working style.
That is basically progressive disclosure through the filesystem.
Instead of building a separate retrieval engine for every instruction, the directory and file structure already tells the system what matters where.
One correction that improves credibility
A lot of people talk about CLAUDE.md as if it is part of the system prompt. Anthropic’s docs are more precise. They say CLAUDE.md is delivered as context, not enforced configuration. That means the file is extremely useful, but it is not a magic compliance switch. Concise, consistent instructions matter more than just having more instructions.
That is exactly the kind of nuance that makes an article like this more credible.
A Better Mental Model for Agent Memory
The cleanest mental model I have found is this:
Context window = working memory
This is the short term area where the model is actively reasoning right now.
Filesystem = durable memory
This is where plans, notes, instructions and outputs live when they need to survive beyond the current turn.
Retrieval layer = recall assistant
This helps the agent find the right file or the right passage when the corpus becomes too large for simple keyword matching.
Database = coordination layer
This becomes necessary when multiple users, multiple agents or stronger consistency guarantees enter the picture.
That is the equilibrium architecture.
Not “files versus databases.”
Files first. Retrieval next. Database when operational pressure makes it unavoidable.
Practical Examples:
Example 1: A research agent
A research agent can keep:
- todo.md for the active work plan
- sources.md for links and references
- notes.md for extracted findings
- draft.md for the evolving output
This works very well because the agent can keep active reasoning focused while offloading bulk material to files.
Example 2: A coding agent
A coding agent can use:
- CLAUDE.md for persistent project instructions
- memory/bug-fixes.md for lessons learned
- memory/build-notes.md for environment quirks
- todo.md for the current refactor or feature branch
This is readable by both the developer and the model, which makes it easy to correct mistakes.
Example 3: A support or ops agent
A support agent can start file first, but if it begins handling:
- multiple customers
- concurrent writes
- permissions
- audit logs
- strict consistency rules
then a database becomes the right move.
That is the key point. You do not start there by default. You move there when the workload actually demands it.
Where Markdown Files Fail
File based memory is powerful, but it is not limitless.
1. Memory bloat
If your core memory files become huge, they start eating tokens every session and the model follows them less reliably. Anthropic explicitly warns that these memory mechanisms are context, not hard enforcement, which is another way of saying clarity matters more than bulk.
2. Contradictions
Large memory files attract stale rules, duplicated instructions and half outdated notes. Once that happens, the agent becomes inconsistent.
3. Concurrency
The moment several agents or several users need to write to the same memory safely, plain files become fragile. That is where databases earn their place.
4. Semantic scale
As the knowledge base grows, grep and keyword search start breaking on paraphrases, synonyms and fuzzy recall. OpenClaw’s public hybrid search configuration is effectively an admission that retrieval eventually becomes necessary.
5. Governance
Enterprise settings need permissions, auditability, policy boundaries and lifecycle management. Files alone are rarely enough there.
What This Means for Builders Right Now
If you are building an agent today, I think the lesson is simple.
Do not overbuild memory on day one.
A lot of teams start with infrastructure because infrastructure looks serious. But agent memory is not won by complexity. It is won by clarity.
Start with the smallest architecture that gives you:
- inspectable state
- durable notes
- predictable context
- easy correction
- low operational cost
For many workflows, that means:
- one live planning file
- one durable memory file
- one folder for dated or topic based notes
- optional semantic indexing over those files later
That is enough to get surprisingly far.
Final Takeaway
The strongest version of this argument is not that Markdown files beat databases forever.
It is that successful agent systems keep rediscovering the same truth: files are an excellent first class interface for memory because they match how language models consume context, how humans debug systems and how teams iterate quickly.
Manus publicly frames the filesystem as context. Anthropic ships CLAUDE.md and auto memory as product features. OpenClaw uses Markdown as the user facing memory surface and layers retrieval on top. Those are three different paths that all point in the same direction.
So if your first instinct is to stand up a vector database before your agent can even keep a clean todo.md, it may be worth pausing.
Start with a file.
Make it readable.
Make it useful.
Then add heavier memory infrastructure only when reality forces you to.
That is usually the better order.








No comments yet. Be the first to comment!